I'm finally here!
I was so busy because of all the APs and school exams.. Now that everything is over I need to really get going!
I will summerize what I've done and where I've to go now.
1. Synchronization of flushing
This is actually very simple to solve. We just make cache tables for each processes and immediately flush the contents (when flush function is called) without any synchronization process. Even when multiple processors open the same file and simultaneously flush the content, we only need some mutex to block the flushing from happening at the same time. This requires no complicated synchronization with processes. First Comes, and First Served! When the flush is requested but the location is already flushed, it signifies that the previous process was occupying the file, and in this case flushing is incomplete and
2. Problem of the Cluster
One problem that I faced when I was implementing the cache system was that the unit of allocation of file system driver is not a sector but a cluster. This caused myriads of problems such as unnecessarily allocating new cluster when there is still usable space in the cluster. I fixed the problem by changing file system driver functions from sectorwise to clusterwise. File system driver now has to provide function that returns the cluster start location(sector address of cluster) corresponding to the linear block address, function that returns the sector count of a cluster, and function that allocates new cluster(not a sector) to a file.
From this...
// Allocate a new block to file
// return : "Sector address"
// unit_size : How many "Sector" is one block allocated by fsdev?
virtual max_t allocate_new_block(file_info *file , max_t &unit_size) = 0;
// Get physical block address of the file
virtual max_t get_phys_block_address(file_info *file , max_t linear_block_addr) = 0;
To this!
/// @brief Translate linear block address into the start address of the corresponding cluster.
/// @param file file
/// @param linear_block_addr Linear block address of file
/// @return Sector address of the cluster
virtual max_t get_cluster_start_address(file_info *file , max_t linear_block_addr) = 0;
/// @brief Get the number of sector that consists one cluster
/// @param file file
/// @return Number of sector of a cluster
virtual max_t get_cluster_size(file_info *file) = 0;
/// @brief Allocate a new blocks to file (allocate one cluster to the file)
/// @param file file
/// @return Start address of the cluster
virtual max_t allocate_new_cluster_to_file(file_info *file) = 0;3. Cache System
a) Overall Structure of System
Cache storages are now created individually for each opening of a file. In a file_info structure, who_opened_list contains the open_info_t structure which contains all the cache storages.
From this...
typedef struct file_info_s {
...
ObjectLinkedList *who_open_list;
// Hash table for file buffer
// Key value : Block location
HashTable *disk_buffer_hash_table;
}file_info; To this!
typedef struct open_info_s {
max_t task_id;
max_t open_flag;
max_t maximum_offset;
max_t open_offset;
// Hash table for file buffer
// Key value : Physical block location
HashTable *cache_hash_table;
// List for newly created blocks
// Key value : Logical block location
ObjectLinkedList *new_cache_linked_list;
}open_info_t; Cache storages consists two containers: container that stores caches for pre-existing blocks in the file and container that stores newly created caches. Pre-existing caches are stored in Hash Tables, as they are frequently used and requires fast access speed. Newly created caches are stored in linked list, as they have to be easy to access and therefore easy to register to the file.
New caches are created when new space for file is required. Because newly created caches do not have any physical sector address yet, it contains the logical block address instead of physical sector location.
Pre-existing caches are stored in the hash table with the key being the physical sector location of the cache, as the cache blocks needs to be written to the corresponding sector location when flushing.
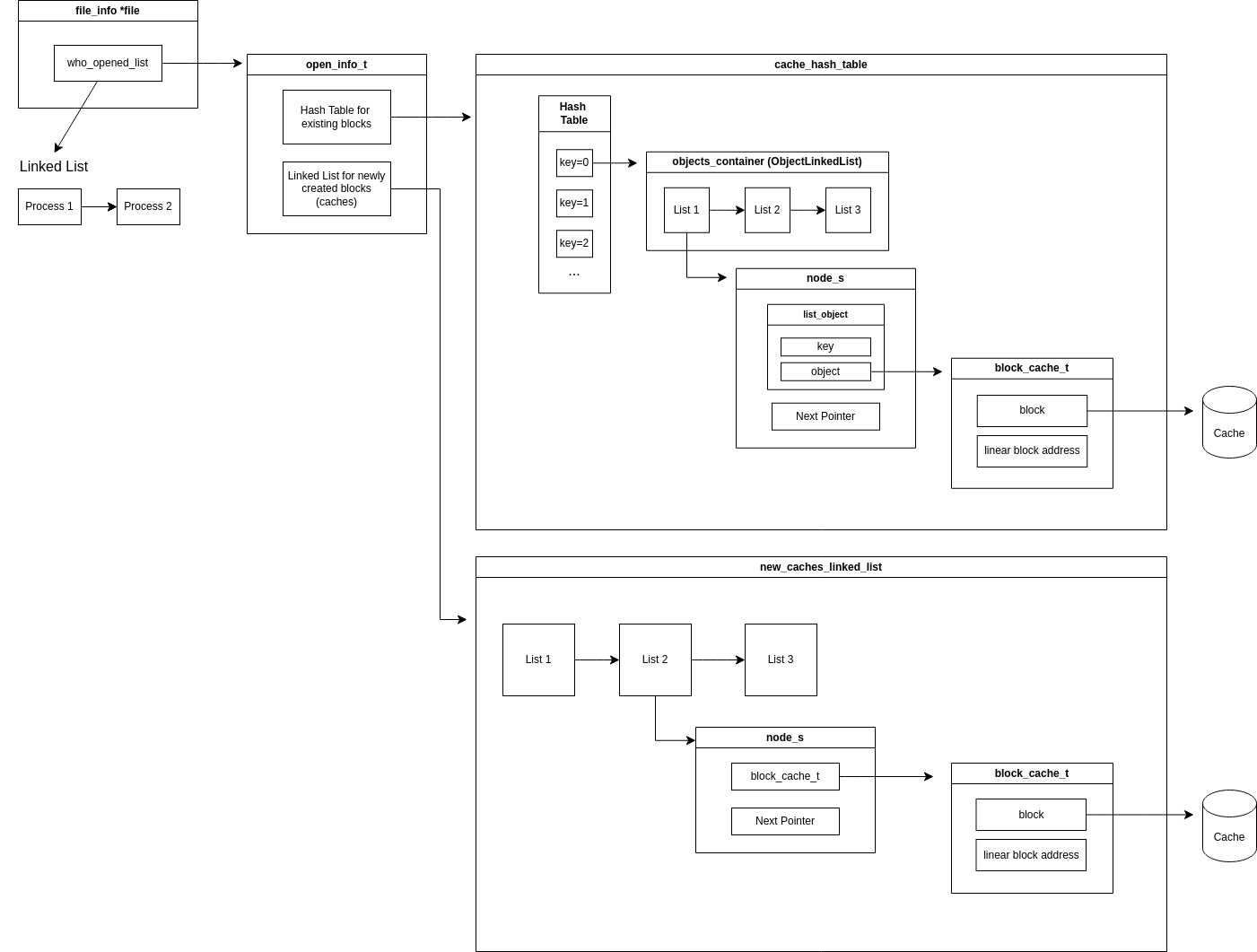
The entire cache storage structure
get_cache_data() function simultaneously creates (if not exist) and searches the cache from the storage in file_info structure. The function gets a linear address of file and returns the corresponding cache structure. When the function detects that the corresponding cache does not exist, it automatically creates new cache structure.
/// @brief Get the cache object from the cache storage. New cache object is automatically created when the cache does not exist.
/// @param file File handle
/// @param linear_block_addr Linear block address
/// @param open_info Information about file open
/// @return block cache object
static block_cache_t *get_cache_data(file_info *file , max_t linear_block_addr , open_info_t *open_info) {
block_cache_t *cache;
physical_file_location *file_loc = fsdev::get_physical_loc_info(file);
max_t block_size = file_loc->block_device->geometry.block_size;
max_t cluster_size = file_loc->fs_driver->get_cluster_size(file);
max_t cluster_start_phys_location = file_loc->fs_driver->get_cluster_start_address(file , linear_block_addr);
if(cluster_start_phys_location == INVALID) {
// Out of the bounds, search from new_cache_linked_list
ObjectLinkedList::node_s *n = open_info->new_cache_linked_list->search([](block_cache_t *o,max_t l){return o->linear_block_addr == l;} , linear_block_addr);
if(n != 0x00) return n->object;
return 0x00;
}
// actual physical location of the block
max_t block_phys_location = cluster_start_phys_location+(linear_block_addr%cluster_size);
cache = open_info->cache_hash_table->search(block_phys_location);
if(cache != 0x00) return cache;
ObjectLinkedList::node_s *n = open_info->new_cache_linked_list->search([](block_cache_t *o,max_t l){return o->linear_block_addr == l;} , linear_block_addr);
if(n != 0x00) return n->object;
// we actually need to create new cache page now..
// cache does not exist, create new cache
debug::out::printf("cluster location : %d\n" , cluster_start_phys_location);
unsigned char *temp_buffer = (unsigned char *)memory::pmem_alloc(cluster_size*block_size);
file_loc->block_device->device_driver->read(file_loc->block_device , cluster_start_phys_location , cluster_size , temp_buffer);
block_cache_t *caches_ptr[cluster_size];
for(max_t i = 0; i < cluster_size; i++) {
cache = (block_cache_t *)memory::pmem_alloc(sizeof(block_cache_t));
cache->block = (void *)memory::pmem_alloc(block_size);
memcpy(cache->block , temp_buffer+(i*block_size) , block_size);
cache->block_size = block_size;
cache->flushed = true; // newest version.
// add to the cache table
open_info->cache_hash_table->add(cluster_start_phys_location+i , cache);
// block device as a unit
caches_ptr[i] = cache;
}
memory::pmem_free(temp_buffer);
return caches_ptr[linear_block_addr%cluster_size];
} Notice the cache structures is created for the entire cluster corresponding to the linear address, instead of only creating one cache structure of one sector corresponding to the linear address(See the for loop at the end of the function.)
b) Flushing System
There are two steps for flushing the cache contents. First, flush the pre-existing cache files. Second, flush the newly created cache files.
First step is very rudimentary, as it consists of just reading all the hash table contents and writing the unflushed content to disk. flush_preexisting_cache() circulates all the contents in the hash table and apply the changes(caches that flushed = false) to the disk.
static bool flush_preexisting_caches(HashTable*preexist_caches , file_info *file) {
bool succeed = true;
physical_file_location *file_loc = fsdev::get_physical_loc_info(file);
debug::out::printf("max_index : %d\n" , preexist_caches->max_index);
// circulate all the hash table contents
for(int i = 0; i < preexist_caches->max_index; i++) {
if(preexist_caches->hash_container[i].objects_container == 0x00) continue;
ObjectLinkedList::list_object>*linked_lst = preexist_caches->hash_container[i].objects_container;
ObjectLinkedList::list_object>::node_s *node_ptr = linked_lst->get_start_node();
while(node_ptr != 0x00) {
max_t block_loc = node_ptr->object->key; // key : block_loc
if(node_ptr->object->object->flushed == true) {
node_ptr = node_ptr->next;
continue;
}
debug::out::printf("flushing preexisting cache : addr %d\n" , block_loc);
node_ptr->object->object->flushed = true;
if(file_loc->block_device->device_driver->write(file_loc->block_device , block_loc , 1 , node_ptr->object->object->block)
!= file_loc->block_device->geometry.block_size) node_ptr->object->object->flushed = false;
node_ptr = node_ptr->next;
}
}
return succeed;
} Second step is a bit complicated than the first. The step consists of reading all the cache entries in the linked list and write those new cache data to the new clusters. New clusters are allocated using the file system driver.
static bool flush_new_caches(ObjectLinkedList*new_caches , file_info *file , open_info_t *who_opened , HashTable*preexist_caches) {
bool succeed = true;
max_t new_block_count = new_caches->count;
max_t flushed_block_count = 0;
max_t created_block_count = 0;
physical_file_location *file_loc = fsdev::get_physical_loc_info(file);
ObjectLinkedList::node_s *start_node = new_caches->get_start_node();
ObjectLinkedList::node_s *ptr = start_node;
max_t blockdev_bs = file_loc->block_device->geometry.block_size;
debug::out::printf("Total new caches count : %d\n" , new_block_count);
if(new_block_count == 0) return succeed;
while(created_block_count <= flushed_block_count) {
max_t cluster_size = file_loc->fs_driver->get_cluster_size(file);
max_t physical_loc = file_loc->fs_driver->allocate_new_cluster_to_file(file);
debug::out::printf("allocated %d sectors\n" , cluster_size);
debug::out::printf("physical location : %d\n" , physical_loc);
for(int i = 0; i < cluster_size; i++) {
if(ptr == 0x00) {
break;
}
if(file_loc->block_device->device_driver->write(file_loc->block_device , physical_loc+i , 1 , ptr->object->block)
!= blockdev_bs) succeed = false;
ObjectLinkedList::node_s *node_to_remove = ptr;
ptr = ptr->next;
// Add the flushed node to the pre-existing hash table, remove from new cache list.
node_to_remove->object->flushed = true;
preexist_caches->add(physical_loc+i , node_to_remove->object);
new_caches->remove_node(node_to_remove);
debug::out::printf("writing the cache data to %d\n" , physical_loc+i);
}
if(ptr == 0x00) break;
created_block_count += cluster_size;
}
return succeed;
} 4. Future
Now... I want to make system for executing a external program.. so I need these following steps.
- Create task management system
- Implement paging system and (universal) virtual memory system
- Improve the memory allocation system (allocate page?)
- Create the executable file loader
- Etc..
I will finish up the file system stuff and get right into developing the task management system! Lots of things to do...